Pourquoi vos applications Cloud AWS plantent le lundi matin ?
Découvrez pourquoi vos applications cloud plantent chaque lundi et comment éviter le syndrome du restart post-weekend avec des solutions AWS optimisées.

Lundi matin, 9h. Vos applications AWS EC2 ou vos conteneurs Docker semblent toujours avoir du mal à redémarrer correctement. Et vous n'êtes pas seul. Derrière ce "syndrome du restart post-weekend", il y a des erreurs systématiques qui pourraient être évitées avec la bonne configuration de vos infrastructures cloud et une meilleure approche DevOps.
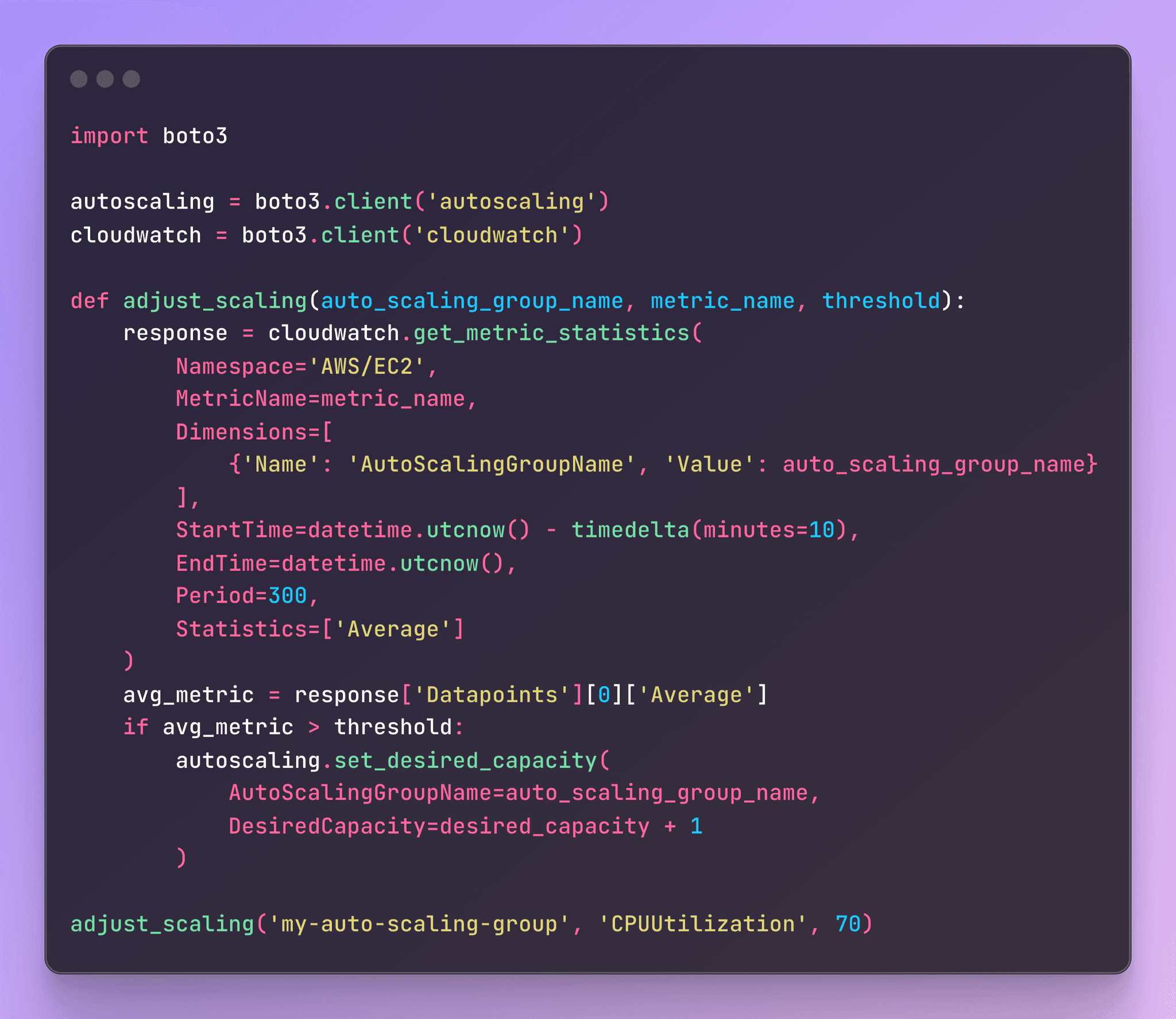
Mauvais scaling de vos services AWS
Pendant le week-end, vos instances AWS EC2 tournent souvent au ralenti. Mais lundi, le trafic explose. Mal configurés, vos groupes de scaling automatique (Auto Scaling Groups) ne répondent pas à la demande. Résultat : lenteurs ou crashs.
La solution ? AWS CloudWatch pour surveiller les métriques et ajuster les paramètres de scaling à partir des données historiques.
Bases de données RDS en désynchronisation
Les bases de données AWS RDS mal synchronisées sont une autre cause de soucis. Si vos clusters n'ont pas synchronisé les écritures du week-end, l'afflux de requêtes le lundi peut mener à des erreurs. Vérifiez vos règles de replication et assurez-vous que vos bases sont prêtes pour les pics de charge.
-- Vérification de la réplication sur une base de données MySQL RDSSHOW SLAVE STATUS\G
-- Assurez-vous que 'Seconds_Behind_Master' est proche de zéro
Conteneurs Docker mal gérés
Si vos micro-services tournent sur des conteneurs Docker, il est crucial de s'assurer que Kubernetes (ou tout orchestrateur que vous utilisez) est bien configuré pour redémarrer les pods en cas de surcharge. Pensez à des stratégies de redéploiement intelligentes, utilisant des probes d'aptitude (liveness probes) pour éviter les interruptions.
# Exemple de configuration Kubernetes avec une liveness probe
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-app-container
image: my-app-image
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 10
Le lundi ne devrait pas être synonyme de cauchemar. Avec la bonne approche DevOps, une meilleure gestion de vos services cloud AWS et des outils de monitoring adaptés, vous pouvez éviter le syndrome du restart post-weekend et assurer la stabilité de vos applications.



